Marko Oja
Data-arkkitehti, joka auttaa asiakasta ymmärtämään tekniikan mahdollisuudet ja muuntaa innovatiiviset ideat teknisiksi ratkaisuiksi. Ketterät kehitysmenetelmät ja kehitystyötä tukevat prosessit ovat lähellä Markon sydäntä.
Jos seuraat datamaailman trendejä, niin olet varmaankin kuullut jo Data Lakehousesta. Se on Databricksin ehdottama arkkitehtuuri, joka käyttää Delta-tauluja tietoaltaan tallennusmuotona.
Mutta mitä se oikeastaan tarkoittaa? Lähimmäksi todellisuutta osuvan määritelmän, jonka olen löytänyt, on tämä (vapaasti käännettynä):
”Lakehouse on uusi avoin arkkitehtuuri, joka yhdistää tietoaltaiden ja tietovarastojen parhaat osat. Lakehouset hyödyntävät uutta, avointa ja standardoitua järjestelmärakennetta: se toteuttaa samankaltaisia tietorakenteita ja tiedon hallinta ominaisuuksia, kuin joita on tietovarastoissa, suoraan sellaisen edullisen varastoinnin avulla jota käytetään tietoaltaissa.” https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
Täytyy myöntää, että minulla on kevyt vihasuhde hype-termeihin. Tekniset ideat näiden ilmiöiden taustalla ovat suurimmaksi osaksi järkeviä ja välillä jopa hämmästyttäviä. Ongelmia alkaa syntyä, kun nuo ideat alkavat elää omaa elämäänsä, ja kehittyvät maagisiksi yksisarvisiksi, jotka ratkaisevat kaikki ongelmat ja tekevät kaikki olemassa olevat teknologiat turhiksi. Tällaiset lupaukset kaiken ratkaisevista ominaisuuksista ei ole realisoitunut edellisten hypejen myötä, eikä sellainen todennäköisesti tule tapahtumaan tulevienkaan myötä. Joten, jos emme tarkastele näitä ilmiöitä sopivalla kriittisyydellä, niin juoksemme milloin minkäkin uuden ajatuksen perässä, tai pahimmillaan teemme hätiköityjä päätöksiä arkkitehtuurin suhteen. Kääntöpuoli on se, että on aivan yhtä vahingollista, olla yrittämättä ymmärtää mitä nämä uudet teknologiat ovat ja miten niistä voidaan aivan oikeasti saada hyötyjä.
Lupaavien teknologioiden kategoria on se, minne itse sijoittaisin Data Lakehouse -arkkitehtuurin monien muiden hypejen tavoin. Lakehousen tapauksessa olemme jo nähneet sen tuotannossa suoriutuvan hyvin tietyissä käyttötapauksissa, joissa perinteinen tietovarastoarkkitehtuuri jää vajanaiseksi. Ja se on näyttänyt tavallista enemmän lupausta muutamissa tapauksissa, kuten esimerkiksi IoT-striimin varastoinnissa. Lisäksi sillä on potentiaalia automatisoida persistoidun staging-alueen kehitys, toisin sanoen raakatiedon historian tallennus. Historiakäsittely on yksi niistä tehtävistä, joka on tavallisesti nähty joihin perus tietoaltaat eivät kykene, ja joka on nähty tietovarastopalvelun vastuuna. Tämän lisäksi on tapauksia kuten kuvien tallennus Delta-tauluihin, joita en haluaisi edes ajatella toteutettavan perinteisillä SQL-teknologioilla. Joten voidaan sanoa, että on olemassa päteviä teknisiä kyvykkyyksiä Data Lakehouse hypen takana.
Aika monen sellaisen asiakkaan kanssa, joiden kanssa olen päässyt keskustelemaan Databricksin käytöstä, yksi yleisimpiä käsityksiä on ollut, että sen hyödyntäminen vaatii koodausta. Vaikka tämä ei ole kovin kaukana totuudesta, ei se silti ole aivan koko kuva. Databricks ja vielä tarkemmin Delta-taulut / Data Lakehouse ovat jotain mitä voidaan hyödyntää ilman, että tarvitsee kehittää yhtään koodia.
Tämä yleisesti omaksuttu ajatus siitä, että Spark-pohjainen kehitys vaatii koodausta, tulee aika tuoreesta historiasta, kun se itseasiassa piti paikkansa. Olen aina ollut sitä mieltä, että low-code -ratkaisut ovat useimmiten kustannustehokkaampia, koska kehitys- ja ylläpitokulut ovat huomattavasti alhaisemmat verrattuna kooditoteutuksiin. Joten, koska nämä kulut muodostavat suurimman osan data-alustan kokonaiskustannuksista, on järkevää olla huolellinen ”pitkästä puusta” koodattavien ratkaisujen käytössä silloin, kun se ei ole pakollista tai hyvin perusteltua.
Hyvä uutinen on että myös Databricksillä datakehitystä voi tehdä koodaamatta riviäkään. No, melkein riviäkään. Joitakin tuotantoympäristön pystytyksessä tarvittavia kohtia täytyy tehdä koodia käyttäen. Kuitenkin varsinaisessa datakehityksessä, kuten uuden taulun lisäämisessä olemassa olevasta lähteestä, ei ole tarvetta käyttää mitään muuta kuin Data Factorya ja SQL:ää Databricksissä. Toisin sanoen tarvittava tietotaito on erittäin lähellä perinteisen tietovaraston kehitykseen tarvittavia taitoja. Ainakin Azuressa.
Seuraavan latausmallin ei ole tarkoitus olla referenssiarkkitehtuuri tai kuvata hyvää käytäntöä, vaan on lähinnä tarkoitettu todistamaan konseptin käytettävyyttä. Kuitenkin se tuottaa hyvin yksinkertaisen, mutta kuitenkin erittäin tavallisen latausmallin, jota käytetään tietovarastoinnissa. Lähde tiedostoista ladataan data kolmeen staging-tauluun, joissa tallessa on aina vain viimeisin tietojoukko. Noiden taulujen päällä on näkymä kerros, jotka tarkistavat avainten yksilöllisyyden dimensioille ja määrittelevät transformaatiot kaikille tauluille. Näiden näkymien tiedoista ladataan kaksi dimensiotaulua (person & manager), sekä yksi fakta-taulu (job_history). Lataus on toteutettu käyttäen SQL Merge -syntaksia, joka estää duplikoidun datan tallentamisen lopullisiin tauluihin. Lopputulos on hyvin yksinkertainen tähtimalli, jossa on kaksi dimensiota ja faktataulu. Alku tietomallille.
Toteutettu lataus prosessi toimii seuraavalla tavalla:
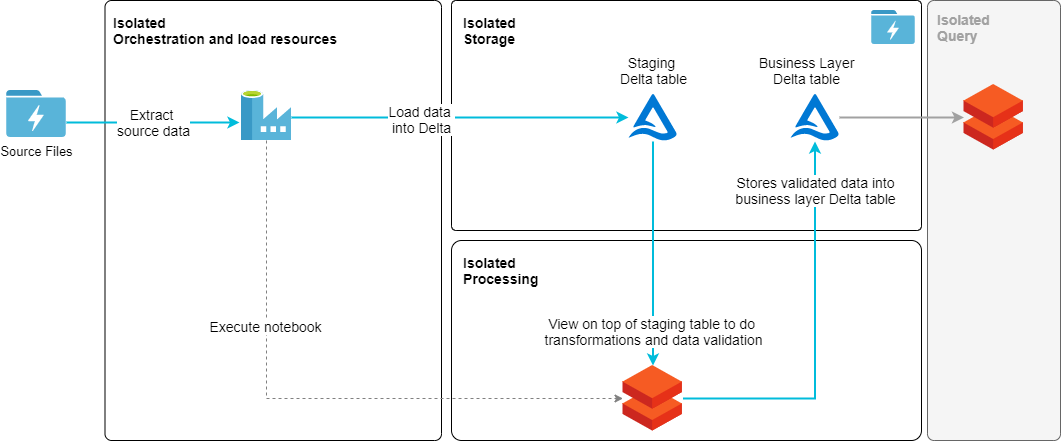
Tietomallin luomiseksi tai varsinaisen lataus prosessin toteuttamiseksi ei ollut tarve käyttää ei käytetty lainkaan Python-, Scala- tai mitään muutakaan koodia.
Suunnitteluohjenuorista Data Lakehouse -arkkitehtuurissa kaksi ovat eristää prosessointikerros tallennuskerroksesta ja minimoida tallennukseen käytettävien palveluiden käyttö, sekä näin minimoida tiedon monistanen. Kuten edellisessä arkkitehtuurikuvassa näkyy, juuri näin on tapahtunut. Tieto on tallennettu pelkästään Storage Accountiin. Lisäksi, kun Data Factory on valittu orkestroimaan koko prosessia, se luo toteutukseen yhden eristyskerroksen lisää. Vaikka Databricks onkin hyvin tehokas laskentapalvelu, ei se kuitenkaan ole missään tapauksessa integraatiotyöväline. Yleisessä toteutuksessa olisi lisäksi tarve eriytetylle kyselykerrokselle Delta-taulujen päälle, kuten erillinen Databricks-klusteri, joka palvelisi BI- ja AI-kyselyitä (harmaa laatikko kuvan oikealla reunalla).
Yksi asia, jota erityisesti arvostan Data Lakehouse arkkitehtuurissa, on erillisten moduulien eristäminen toisistaan. Voimme näin tallentaa dataa samaan fyysisiin tauluihin striimeistä, eräajoista, rajapinta eventeistä tai manuaalisista syötöistä. Lisäksi kaikki prosessointi mitä tarvitaan tiedon lataamiseksi ja transformoimiseksi voidaan eriyttää erittäin tarkalle tasolle. Mikään ei itseasiassa estä käyttämästä edes joka ikiselle lataukselle dedikoitua konetta, jos niin haluaisimme. Varmasti eristämisessä päästään siis tasolle, joka olisi erittäin vaikea saavuttaa monella muulla ratkaisulla. Mutta tärkeämpää tässä on se, että se jättää yleisen arkkitehtuurin avoimeksi siten, että siinä pystytään helposti hyödyntämään erityyppisiä palveluita tai moduuleita kuten Datan laadun tarkistus, kun niille on tarvetta. Tarpeet voivat muodostua niin kehityksen ja ylläpidon helppouden kuin tiedon tehokkaan käsittelyn näkökulmasta.
Voimme lopuksi todeta, että uusista ja kiiltävistä asioista hyötyminen ei aina tarvitse olla liiallisen monimutkaista. Väittäisinkö, että tämä arkkitehtuuri poistaa täysin tarpeen tietovarastoille? Ei, en väittäisi. Mutta se tekee osasta tietoalustakehityksestä ja toteutuksesta entistä virtaviivaisempaa, ja täten omasta elämästäni pikkuisen helpompaa. Joten itse ainakin kannustan tämän teknologian puolesta.
Jälkimainintana, jos olet kiinnostunut todellisesta toteutuksesta, niin täältä löytyy englanninkielinen kuvaus teknisistä vaiheista: https://www.cloud1.fi/en/blog/data-lakehouse-with-low-code-implementation
Lisäksi jos haluaisit vaihtaa ajatuksia tästä tai muista Azuren tietoalustatoteutuksissa, niin meihin voi mielellään olla yhteydessä: marko.oja@cloud1fi ja myynti@cloud1.fi