Marko Oja
Marko helps customers to understand the endless possibilities of technology and to transform innovative ideas into technical solutions. Agile methods and process development are close to his heart.
If you follow any trends in data world, you have probably heard about Data Lakehouse. It’s a new architecture proposed by Databricks that utilises Delta tables as data lake storage format.
But what is it exactly? A closest to real-world definition that I have come across with is this:
”A lakehouse is a new, open architecture that combines the best elements of data lakes and data warehouses. Lakehouses are enabled by a new open and standardized system design: implementing similar data structures and data management features to those in a data warehouse, directly on the kind of low-cost storage used for data lakes.”
https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
I admit that I have a slight hate relationship to hype terms. Technical ideas behind these phenomena are most of the times something reasonable and sometimes even amazing. Problems comes when these ideas start to live their own lives and evolves into magical unicorns that solve all problems and makes all existing technologies obsolete. This promise of all solving capability haven’t actualised with any of the previous hypes and most probably won’t happen with the new ones either. If we don't take these hypes with a heavy grain of salt we will be running after new ideas all the time. In worst case this leads to making haste decisions on architectures. The flip side is that it is equally hurtful not to try to understand what these new technologies are and how we can really take advantage of them.
A promising technologies category is where I would put Data Lakehouse architecture among with many other hypes. We have already seen it perform well in production for specific use cases where traditional data warehouse architecture falls short. And it has shown way more than a little promise when it comes to, for an example, IoT data storing scenarios. It has also the potential to automate development of persistent staging layer, in other terms maintain history for raw data. History handling has been one of those features that basic data lakes are not capable of and has been responsibility of data warehouse services. And then there are things like storing images into Delta table, which I wouldn’t even like to think to implement with traditional SQL technologies. So there definitely are valid technical capabilities behind all this hype about Data Lakehouse.
With quite many of the customers, I have talked with about using Databricks, one of the most common impressions has been that we must do coding to use it. Although this is not far from the truth, it is not the whole truth. Databricks and more specifically Delta tables / Delta Lakehouse is something you can leverage without doing any coding.
The generally adopted idea that spark cluster development is code-based comes from quite recent history where this was the case. I have always seen that low code solutions in most cases are more cost-efficient because development and maintenance costs are much lower compared to code implementations. So as development and maintenance efforts make the most of the overall costs of a data platform it makes sense to be careful not to use code where it is not mandatory or well-argued.
The good news is that also Databricks data development can be done without using a single line of code. Well, almost none. There are some parts that in production environment needs to be set up using a few lines of code. However, in the actual data development, like adding a new table from an existing source, there is no need to use anything but Data Factory and SQL code in Databricks. In other words, needed knowledge set is extremely close to traditional data warehouse development skills at least in Azure.
The following pattern is not supposed to be a reference architecture or a best practice solution but rather a proof-of-concept implementation example. That said it does produce a basic but very common load pattern used in data warehouses. From source data files, three staging tables are loaded. On top of those tables, there are views that enforce unique keys for dimensions and transformations for all data. From these views of two-dimension tables (person & manager) and a single fact table (job_history) are loaded. Load is implemented using SQL merge syntax to validate that we don’t load duplicate data into the business layer. The result is a very simple star schema model with two-dimension tables and a fact table. A start of a data model.
The actual load pattern goes like this:
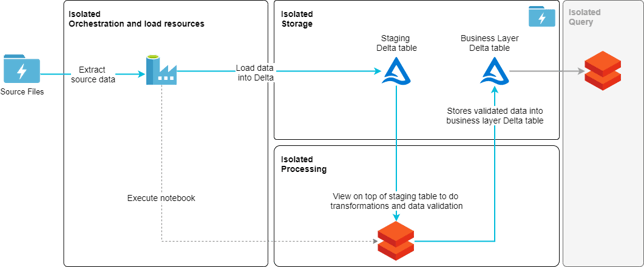
To create the table structures or to implement the actual load pattern, no Python, Scala or other code were used or needed.
Two of the design guidelines of a Data Lakehouse architecture are to isolate processing from a storage layer and to minimize the number of separate services storing data and by this minimizing duplication of data. As shown in the architecture diagram this is exactly what has been done. Data is stored solely in storage account. Also, as Data Factory is the chosen orchestration service it creates one extra layer of isolation to the stack. After all, Databricks is a very powerful computation service but an integration service it is not. Generally speaking, on top of business layer delta tables we would need a query layer, like for an example a Databricks cluster, dedicated for BI and AI queries (grey box on the right side of the image).
One of the things I appreciate most in Data Lakehouse design is the isolation of different modules. We can store data to the same physical tables from streams, batch load, API events, or manual inputs. And all the processing needed to store and transform this data can be isolated to very low level if wanted. Nothing would prevent us from using dedicated cluster for every single load if wanted. This gives much more options to optimize the “hardware” from both a performance and cost perspective. It does so to a level that is very hard to achieve with most other systems. But more than that it also leaves the architecture open to benefit from other type of services, and modules like Data quality validation, when it is needed either from development and maintenance easiness or performance point of view.
So, in the end, we can conclude that benefitting from the new and shiny things doesn’t always have to be overly complex. Would I say that this architecture makes data warehouse services obsolete? No, I wouldn’t. But it can make some parts of data platform development and implementation considerably more streamlined and because of this my life a bit easier. So, I am rooting for this one.
P.S. If you are interested in the actual implementation, an introduction can be found from here: https://www.cloud1.fi/en/blog/data-lakehouse-with-low-code-implementation
Also, if you like to discuss this or other Azure Data Platform capabilities then please don’t hesitate to contact us: marko.oja@cloud1.fi and myynti@cloud1.fi