Marko Oja
Data-arkkitehti, joka auttaa asiakasta ymmärtämään tekniikan mahdollisuudet ja muuntaa innovatiiviset ideat teknisiksi ratkaisuiksi. Ketterät kehitysmenetelmät ja kehitystyötä tukevat prosessit ovat lähellä Markon sydäntä.
Power BI:ssä, kuten aika monissa muissakin analytiikka välineissä, on aina ollut haasteita, kun siirrytään todella suuriin tietomääriin. Kuten nyt vaikkapa miljardin rivin taulun analysointi. Tällaiseen ongelmaan on pyritty yleensä vastaamaan tallentamalla osa tiedoista analytiikka työvälineen muistiin, jota yleensä on rajoitetusti, ja ohjaamalla sitten tarkennettuja kyselyitä tietokantaan. Vielä muutama vuosi takaperin, testaillessani miten Databricks suoriutuisi Power BI:n suorista kyselyistä, jouduin pettymään. Nopeus ei ihan ollut toiveiden mukaista. Ja tällaisen samanlaisen kommentin kuulin menneellä viikolla myös raportti kehittäjältä. Mutta tokihan nyt jonkin verran asian on täytynyt parantua parissa vuodessa?
Olin kuullut, että managed taulujen (Databricks instanssin omaan storageen tallennetut) tulisi olla nopeampia, kuin "ulkoisella" storagella olevien. Luin myös erään artikkelin delta cachesta, Databricks-klusterin muistiin ajettavasta datasta. Mielessä alkoi kutkuttaa ajatus, että pakkohan nämä kaikki on lyödä yhteen ja päästä testaamaan, josko tekniikka olisi jo kypsynyt riittävästi. Ei muuta kuin vanha 30M rivin datasetti käyttöön ja prosessointi klusteri pystyyn. Näkymät paikalleen ja Power BI raportti pyörimään. Tulokset olivat hämmentäviä.
30 miljoonan rivin testi datasetti ei edes yskäissyt. Mistäs nyt tuulee? Ulkoiselta storagella ja sisäisellä cachella oli lähes huomaamattoman pieni ero nopeudessa. Uuden klusterin olin luonut kaikilla uusimilla versioilla, mutta ero oli aivan liian suuri selittyäkseen pelkästään ohjelmiston version vaihdolla. Käynnistin rinnalle "perus" klusterin, jota käytän tavallisesti kehityksessä. Vaikka nostin versiot samaan tasoon jäi nopeus perinteisemmälle tasolle. Vastaukset kyllä tulivat, mutta hitaasti. Olin napsaissut uudelle klusterille, sen suuremmin ajattelematta, päälle Photon Accelerator:in, josta olin kuullut edellisessä Databricksin esittelytilaisuudessa.
Todellakin viime vuoden (2022) elokuussa Databricks esitteli uuden toiminnallisuuden - Photonin. Tämä uraauurtava kysely moottori pitäisi, ainakin mainospuheiden perusteella, olla jotain aivan ennen näkemätöntä ja ihmeellistä. No näitä lupauksia nyt tulee silloin tällöin, milloin mistäkin. Snowflake on 9 kertaa nopeampi, kuin Azure SQL DW. Databricks on 20 kertaa nopeampi, kuin Snowflake ja niin edelleen. (Disclaimer: En todellakaan tarkastanut lukemia, mutta tämän hehtaarin väitteitä yleensä liikkuu.) Silti kaikki ”kannat” suoriutuvat lähes yhtä tahmaisesti silloin, kun haluttaisiin saada murskattua suuria tietomääriä, ilman data arkkitehtiä hiomassa SQL kyselyä siinä välissä. Näinköhän tämäkin ominaisuus olisi vain mainospuheita ja pörhistelyä?
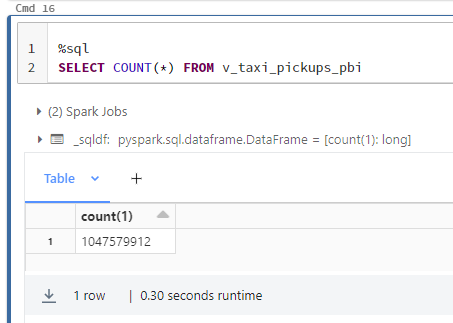 Tarvitsin selkeästi lisää dataa. Nopea netin tutkiminen vei Databricksin kehittäjän blogiin, jossa hehkutettiin 1 miljardin rivin käyttöä Power BI:ssä. No tätähän on aivan pakko päästä kokeilemaan! :D Ensimmäisenä haasteena löytää dataa. Löysin, joillekkin ehkä tutun, New York Taxi-datasetin vuodelta 2021. Valitettavasti siinä ei ollut "kuin" 175 miljoonaa riviä. Pieni datan kerrannaistaminen ja taulusta löytyi rouheat 1,04 miljardia riviä. Datasetti tarjosi myös dimensio datan, johon oli määritelty alueet, joilla taksit toimivat. Tästä saisi ihan aidon tietomallin testattavaksi. Ei muuta, kuin latailemaan.
Tarvitsin selkeästi lisää dataa. Nopea netin tutkiminen vei Databricksin kehittäjän blogiin, jossa hehkutettiin 1 miljardin rivin käyttöä Power BI:ssä. No tätähän on aivan pakko päästä kokeilemaan! :D Ensimmäisenä haasteena löytää dataa. Löysin, joillekkin ehkä tutun, New York Taxi-datasetin vuodelta 2021. Valitettavasti siinä ei ollut "kuin" 175 miljoonaa riviä. Pieni datan kerrannaistaminen ja taulusta löytyi rouheat 1,04 miljardia riviä. Datasetti tarjosi myös dimensio datan, johon oli määritelty alueet, joilla taksit toimivat. Tästä saisi ihan aidon tietomallin testattavaksi. Ei muuta, kuin latailemaan.
Tuskallisen 15 minuutin odottelun jälkeen datat olivat sisässä. Power BI raportti kasaan "minimum effort" mallilla. Ja kyllä se täytyy todeta. Oli se yllättävän nopea. Jotta ei tarvitse luottaa asiassa ainoastaan kehittäjän subjektiiviseen mielipiteeseen, niin ohessa on video, josta pääsee itse seuraamaan Power BI reaktioaikoja. Ihan mitä tahansa kyselyä Power BI ei pystynyt käsittelemään. 10 miljoonan rivin raja tulee vastaan graafeilla. Delta taulut oli partioitu päivämäärän mukaan, ja sen käyttäminen onkin avainasemassa tämän kokoluokan analyysiä tehtäessä. Koko massan yli ajettavatkin tulokset kyllä syntyvät jokseenkin järjellisessä ajassa, mutta kun valitaan vaikkapa viikon data (365 päivästä), niin tulokset ovat kutkuttavia.
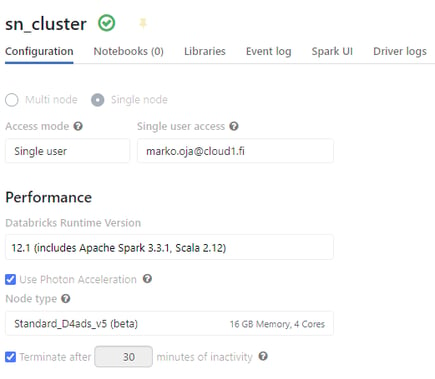 Ja viimeisenä ehkä mieleen saattaa tulla se kustannuspuoli. Minkähän kokoisen mahtipannun tuollainen data määrä oikein vaatii? Ja tässäpä tulee se suurin yllätys. Testi on ensinnäkin tehty Standard (ei Premium) workspacessa. Ja klusteri ei ole oikeastaan edes klusteri. Tai muutenkaan optimoitu ja ylitehoinen kone, vaan General Purpose yhden koneen, siis PELKÄN driver noden kokoinen. Neljällä ytimellä ja 16GB muistia. Ei siis ihan se pienin mahdollinen, mutta ei kovin paljoa suurempikaan. Kun pienin mahdollinen kone on hinnoiteltu 0,5DBU:ta tunnissa, on tämän miljardi riviä murskaavan kokoonpanon kustannus ainoastaan 2DBU:ta tunnissa. Kustannus, jatkuvasti päällä olevalle koneelle, olisi tämänhetkisen hinnoittelun mukaan siis 707€/kuukaudessa (ilman vuosisitoumuksia joilla saisi vielä hinnasta osan pois). Jos hyväksytään, että kone sammuu yöksi, niin kustannukset jäävät jopa alle puoleen maksimihinnasta. Ei paha.
Ja viimeisenä ehkä mieleen saattaa tulla se kustannuspuoli. Minkähän kokoisen mahtipannun tuollainen data määrä oikein vaatii? Ja tässäpä tulee se suurin yllätys. Testi on ensinnäkin tehty Standard (ei Premium) workspacessa. Ja klusteri ei ole oikeastaan edes klusteri. Tai muutenkaan optimoitu ja ylitehoinen kone, vaan General Purpose yhden koneen, siis PELKÄN driver noden kokoinen. Neljällä ytimellä ja 16GB muistia. Ei siis ihan se pienin mahdollinen, mutta ei kovin paljoa suurempikaan. Kun pienin mahdollinen kone on hinnoiteltu 0,5DBU:ta tunnissa, on tämän miljardi riviä murskaavan kokoonpanon kustannus ainoastaan 2DBU:ta tunnissa. Kustannus, jatkuvasti päällä olevalle koneelle, olisi tämänhetkisen hinnoittelun mukaan siis 707€/kuukaudessa (ilman vuosisitoumuksia joilla saisi vielä hinnasta osan pois). Jos hyväksytään, että kone sammuu yöksi, niin kustannukset jäävät jopa alle puoleen maksimihinnasta. Ei paha.