Marko Oja
Marko helps customers to understand the endless possibilities of technology and to transform innovative ideas into technical solutions. Agile methods and process development are close to his heart.
In Power BI, like in quite a few other analytics tools as well, there have always been challenges when moving to really large amounts of data. Like now, for example, analyzing a table with a billion rows. This kind of problem has usually been attempted to be answered by storing part of the data in the memory of the analytics tool, which is usually limited, and then directing detailed queries to a database. A few years back, while testing how Databricks would perform against Power BI's direct queries, I was disappointed. The speed was not as expected. And I also heard a similar comment like this last week from a report developer. But surely things must have improved somewhat in last couple of years?
I had heard that managed tables (data stored in the Databricks instance's own storage) should be faster than those on "external" storage. I also read an article about delta cache, data stored in the memory of a Databricks cluster. The thought began to tickle in my mind that it is necessary to put all these together and get to testing. Surely the technology had already matured a bit. Nothing more than using the old 30M row data set and setting up the processing cluster. Views in place and the Power BI report running. The results were confusing.
The report with 30 million row dataset didn't even cough. What in the world is happening here? External storage and internal cache had an almost imperceptibly small difference in speed. I had created a new cluster with all the latest versions, but the difference was far too big to be explained by just changing the software versions. I ran a "basic" cluster alongside which I normally use for development. Although I upgraded the versions to the same ones, the speed remained at a more traditional level. The answers to queries did get processed, but slowly. With the the new cluster, I had clicked on, without a second thought, the Photon Accelerator. Something that I had heard about at the previous Databricks presentation.
Indeed, in August of last year (2022), Databricks introduced a new functionality - Photon. This ground-breaking query engine should, at least based on the marketing claims, be something never seen before and wondrous. Well, we have all hear promises like these from time to time. Like Snowflake is 9 times faster than Azure SQL DW. Databricks is 20 times faster than Snowflake and so on. (Disclaimer: I didn't actually check the figures, but the claims of this ballpark are being made.) Still, all "databases" perform quite sluggish when you need to crunch large amounts of data, without a data architect polishing the SQL queries in between. So, would this feature just be hype and fluff, like so many others before?
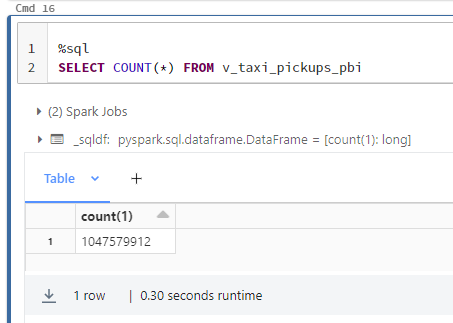 I clearly needed more data. A quick search of the web led me to a Databricks developer's blog that touted the use of 1 billion rows in Power BI. Well, I absolutely had to try this! :D The first challenge is finding enough data. I found a dataset, which some may be familiar with, the New York Taxi dataset from 2021. Unfortunately, it had "only" 175 million rows. A little multiplication of the data and a whopping 1.04 billion rows were available. The data set also offered dimensional data defining the areas where the taxis operated. This would give me a real data model to test on. All was left to do, was to load it into a delta table.
I clearly needed more data. A quick search of the web led me to a Databricks developer's blog that touted the use of 1 billion rows in Power BI. Well, I absolutely had to try this! :D The first challenge is finding enough data. I found a dataset, which some may be familiar with, the New York Taxi dataset from 2021. Unfortunately, it had "only" 175 million rows. A little multiplication of the data and a whopping 1.04 billion rows were available. The data set also offered dimensional data defining the areas where the taxis operated. This would give me a real data model to test on. All was left to do, was to load it into a delta table.
After a painful 15-minute wait, the data was in. Whipped up a Power BI report with a "minimum effort" model. And yes, it must be said: It was surprisingly fast. So that you don't have to rely only on the subjective opinion of the developer (aka. me), here is a video where you can evaluate Power BI report's update times yourself. Some queries Power BI could not handle. The 10 million row limit is restricting the graphs. Delta tables were partitioned by date, and using it is the key when doing an analysis of this magnitude. Calculation results that are run over the entire mass are generated in a fairly reasonable time, but when you select, for example, a week's worth of data (out of 365 days), the results are exhilarating.
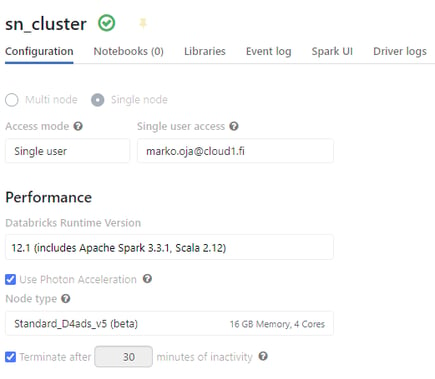 And the last thing that might come to mind is the cost aspect. What size capacity hardware does that amount of data really require? And here comes the biggest surprise. First of all, the test was done on a Standard (not Premium) workspace. And the cluster isn't even a “cluster” aka multiple computers. Or in any way an optimized and overpowered machine, but a General Purpose cluster, size of a single machine, so JUST the size of the driver node. With four cores and 16GB of memory. Not the smallest possible setup, but not much bigger either. While the smallest possible setup is priced at 0.5DBU per hour, the cost of this billion row crushing setup is only 2DBU per hour. The cost in Euros, of running this 24/7, would be €707/month according to the current pricing (without annual commitments that would still take part of the price off). If it is accepted that the machine turns off at night, the costs would be even less than half of the maximum price. Not bad at all.
And the last thing that might come to mind is the cost aspect. What size capacity hardware does that amount of data really require? And here comes the biggest surprise. First of all, the test was done on a Standard (not Premium) workspace. And the cluster isn't even a “cluster” aka multiple computers. Or in any way an optimized and overpowered machine, but a General Purpose cluster, size of a single machine, so JUST the size of the driver node. With four cores and 16GB of memory. Not the smallest possible setup, but not much bigger either. While the smallest possible setup is priced at 0.5DBU per hour, the cost of this billion row crushing setup is only 2DBU per hour. The cost in Euros, of running this 24/7, would be €707/month according to the current pricing (without annual commitments that would still take part of the price off). If it is accepted that the machine turns off at night, the costs would be even less than half of the maximum price. Not bad at all.