Marko Oja
Data-arkkitehti, joka auttaa asiakasta ymmärtämään tekniikan mahdollisuudet ja muuntaa innovatiiviset ideat teknisiksi ratkaisuiksi. Ketterät kehitysmenetelmät ja kehitystyötä tukevat prosessit ovat lähellä Markon sydäntä.
Tosiasia on, että huonolaatuinen data maksaa yritykselle huomattavia summia. Tästä esimerkkinä vaikkapa IBM:n tutkimus vuodelta 2018, jossa arvioitiin huonon datan maksavan pelkästään Yhdysvalloissa 3,1 biljoonaa dollaria vuosittain. Se on iso tukku rahaa. Ja vastaavia tutkimuksia on ollut useita.
Data Ladder:in artikkelissa vuodelta 2020 todettiin huonon datan aiheuttavan seuraavanlaisia vaikutuksia:
Näiden perusteella voidaan mielestäni perustellusti sanoa, että huonosta datasta syntyy konkreettisia negatiivisia vaikutuksia liiketoiminnalle. Ongelma on siinä, miten nämä vaikutukset voitaisiin määritellä ja mitata.
“Huono data maksaa yrityksille arviolta 15% niiden liikevaihdosta.”
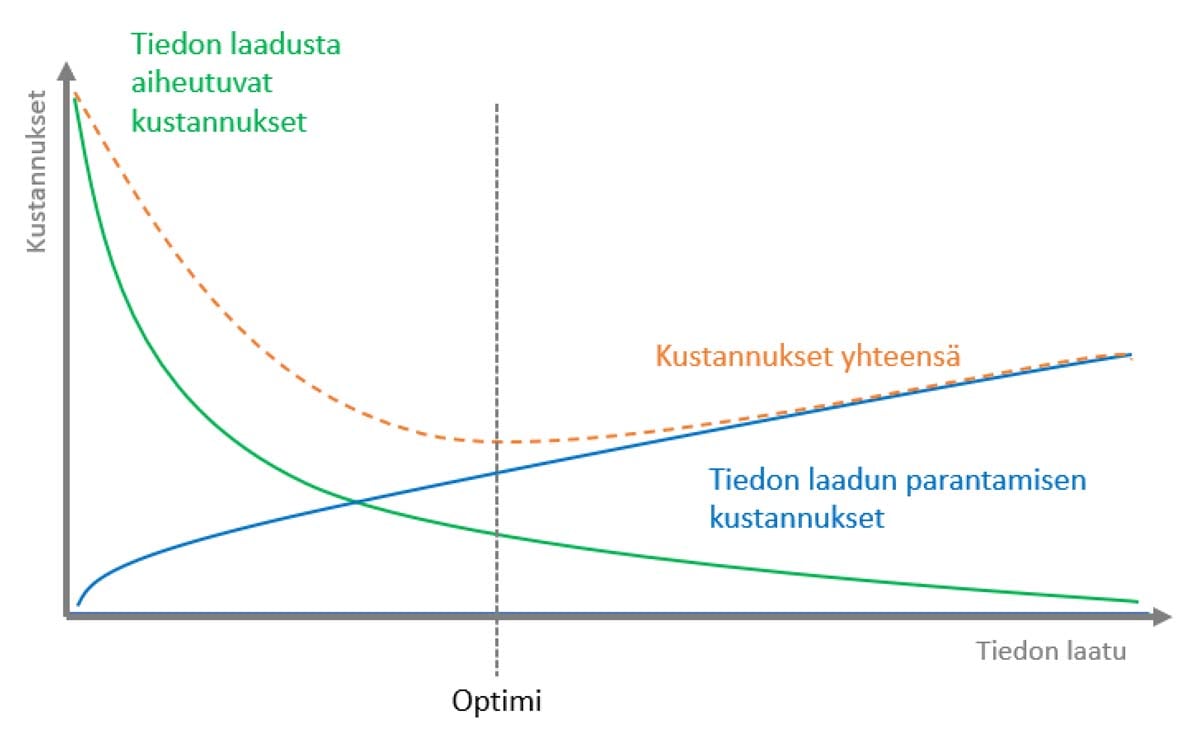
Data laadun vaikutuksen mittaaminen on kokemukseni perusteella vaikeaa. Samaan lopputulokseen on päätynyt moni muukin. Esimerkkinä artikkeli (The costs of poor data quality - Haug, Anders; Zachariassen, Frederik; van Liempd, Dennis), jossa mittaamisen vaikutuksien lisäksi, kuvataan mielestäni toimiva karkean tason käytännöllinen lähestymistapa tiedon laadun vaikutusten kategorisoimiselle. Siinä syntyvät vaikutukset jaetaan neljään erikseen mitattavaan osaan: suorat ja epäsuorat operatiiviset kustannukset, sekä suorat ja epäsuorat vaikutukset strategiseen päätöksentekoon. Lisäksi artikkelissa tuodaan esiin eräs erittäin tärkeä ajatus: tiedon laadussa ei käytännössä koskaan saavuteta 100 prosentin tasoa. Tästä syystä siinä ehdotetaankin etsimään tiedon laadun parantamisen kustannusten ja huonon datan aiheuttamien kustannusten suhteesta sitä optimaalista pistettä, missä näiden kustannusten yhteenlaskettu summa on pienimmillään.
Riippumatta siitä, ollaanko samaa mieltä tämän artikkelin kanssa siitä, mitä ongelmia viallinen data voi aiheuttaa ja miten niitä tulisi mitata, yksi asia on kuitenkin melko itsestään selvä: kyseessä on kompleksi monitahoinen ongelma. Ei ole olemassa mitään helppoa, yksiselitteistä ja suoraa tapaa arvioida huonon tiedon vaikutuksia liiketoimintaan. Olemassa ei ole myöskään yhteistä näkemystä siitä, kuinka suuri huonon datan vaikutus todellisuudessa on. Mielestäni kuitenkin artikkelin ajatus siitä, että tiedon laadun parantamiseen kannattaa panostaa, ja panostuksen suuruus arvioidaan siitä saatujen hyötyjen suhteen, on looginen ja hyvin perusteltu.
Useissa eri tutkimuksissa, raporteissa ja analyyseissä (kuten The Impact of Poor Data Quality on the Typical Enterprise, Thomas C. Redman) todetaan, että huonosta tiedon laadusta aiheutuvat kustannukset liikkuvat suuruudeltaan 5-30% yritysten liikevaihdosta. Vaikka pysyisimme tässä skaalassa hyvin lähellä matalamman pään arvioita, on kyseessä silti huomattava rahamäärä. Mutta kuinka moni yritys sitten aktiivisesti panostaa tiedon laadun parantamiseen rahamäärää, joka vastaa useita prosentteja sen liikevaihdosta? Oman kokemukseni mukaan ei kovinkaan moni. Ei ainakaan siten, että sellainen kustannus olisi suoraan kohdistettu tähän nimenomaiseen tarkoitukseen. Sen sijaan ongelmien selvittämisestä syntyy varmasti näiden tutkimusten osoittamia epäsuoria kuluja, jotka hukkuvat operationaalisten kulujen joukkoon, esimerkiksi siitä, miten työtekijät käyttävät aikaansa, jotta heidän varsinaiset tavoitteensa olisi mahdollista täyttää.
Mistä kaikesta nämä kustannukset sitten tarkalleen ottaen koostuvat? BI-Surveyn ja monien muiden vastaavien tutkimusten mukaan, kustannukset syntyvät datan korjaamisesta, siitä että dataan ei luoteta, ja siitä että viallinen data aiheuttaa viallisia päätöksiä. Se, että dataan ei luoteta, aiheuttaa useita erillisiä ongelmia, kuten tietosiilojen syntymistä ja raporttien tarjoaman tiedon sivuuttamista, jotka taas ruokkivat ongelmaa entisestään. Tutkimus listaa yleisimpiä tiedonlaadun haasteita, joita nykyään kohtaamme:
Työntekijät eivät käytä BI-työkaluja, koska eivät luota niihin tai niiden käyttämään tietoon
Epätarkka tieto johtaa virheellisiin faktoihin ja huonoihin päätöksiin tietojohtamiseen tukeutuvissa ympäristöissä
Tiedon laadun prosessien puuttuminen aiheuttaa useiden datakopioiden syntymisen, ja näiden siivoaminen voi olla kallista
Puuttuvat yhdenmukaiset käytännöt tiedon laadun prosesseissa luovat epäjohdonmukaisuuksia ja uhkaavat sisällöllisiä standardeja
Tietosiilojen muodostumisen ehkäisemiseksi täytyy tiedon välityksen olla yhdenmukaista, jotta eri järjestelmät pystyvät keskustelemaan keskenään
Big datan hyödyntämiseksi tieto tarvitsee liiketoiminnallisen kehyksen eli tieto on linkitettävä liiketoiminnalliseen käsitteistöön
Perspektiivin siirtyminen tietoon (järjestelmien sijaan), vaatii uuden näkökulman, jossa tieto erotetaan lähteestä ja sille muodostetaan yleisiä sekä ominaisia tiedon laadun vaatimuksia
“Tiedon laadussa ei käytännössä koskaan saavuteta 100 prosentin tasoa.”
Tiedon laadun vaikutukset ovat tutkitusti todellisia ja huomattavia. Kyseessä on monimutkainen ongelma ilman yhtä helppoa ratkaisua, ja jos joku väittää muuta, niin suhtautuisin väitteeseen suurella varauksella. Kuten monen muunkin ongelman ratkaisun, tulisi myös tiedon laadun ongelmien ratkaisun lähteä niiden määrittelemisestä ja mittaamisesta. Näiden lisäksi on huomioitava uuden tyyppisten sisäisten ja ulkoisten tietolähteiden vaikutus tiedon laadun hallinnan prosesseihin. Useimmat nykyisistä tiedon laadun parantamiseen tarkoitetuista järjestelmistä nojaavat vahvasti perinteiseen MDM-ajatteluun, mikä todellakin on edelleen erittäin tärkeää, mutta ei kuitenkaan ratkaise kaikkia modernin data platformin tiedonlaadullisia ongelmia.