Marko Oja
Data-arkkitehti, joka auttaa asiakasta ymmärtämään tekniikan mahdollisuudet ja muuntaa innovatiiviset ideat teknisiksi ratkaisuiksi. Ketterät kehitysmenetelmät ja kehitystyötä tukevat prosessit ovat lähellä Markon sydäntä.
Edellisissä osissa käytiin läpi arkkitehtuuri sekä kokemukset kehityksestä. Tässä osassa käyn läpi miten laskennan hajautus käytännössä vaikuttaa ajoaikoihin ja miten tämä vaikuttaa tuotantoratkaisun kustannusten arvioimiseen.
Seuraavaksi kasvatin tietomassan 10 GB:iin eli lähes 17-kertaiseksi. Tämän jälkeen tuplasin laskentatehon lisäämällä toisen identtisen laskenta-noden. Lähtökohtaisesti odotuksena oli ajoaikojen nousu noin 8–9-kertaiseksi. Tiedon latausaika jäi reiluun kuuteen minuuttiin, ja aggregointi jäi vajaaseen kolmeen minuuttiin. Kasvu oli siis odotetusti noin 8-kertainen.
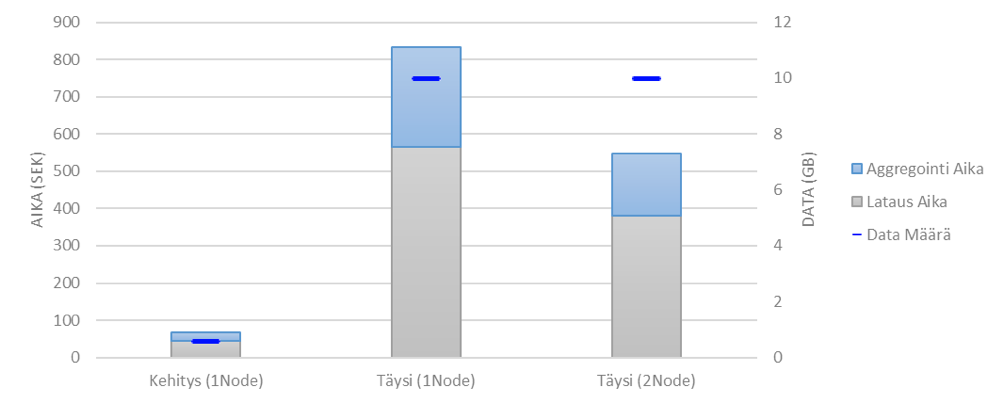
Kuvassa on esitelty miten datasetin kasvattaminen vaikutti ajoaikaan identtisellä kokoonpanolla (kaksi ensimmäistä pylvästä). Sekä miten yhden laskenta noden lisääminen (eli laskennan hajauttaminen) vaikutti ajoaikaan (kaksi viimeistä pylvästä).
Vaikka datamäärä nostettaisiin 100 GB:iin, pärjätään vielä aika pienillä palvelintehoilla. Datan määrän kasvaessa tästä esimerkiksi 1 TB:iin, alkaa mieleen tulla, että palvelinkapasiteettia voisi toden teolla nostaa. Klusterinhan täytyy olla päällä tässä tapauksessa ainoastaan latausten ja analysoinnin ajan. Lisäkehityksen voi tehdä pienemmällä datamäärällä ja kevyemmällä laskentateholla. Onneksi klusterin tehojen muokkaaminen onnistuu muutamassa minuutissa, ja kiireen sattuessa voidaan tehot nostaa nopeasti korkeammalle. Klusterin käyttöastetta on helppo seurata hallintapaneelista, ja näin erityyppisten kokoonpanojen vertailemista voi tehdä muutenkin kuin ajoaikojen perusteella.
Lopputuloksena voidaan todeta, että tietomäärät ovat helposti hallittavissa boostaamalla klusterin tehoja ylöspäin. Mikäli tietoja ajetaan ja hyödynnetaan tarpeen mukaan, niin suuremmatkaan kokoonpanot eivät aiheuta valtavia kustannuksia. Klustereiden määrässä ja laadussa kannattaa toki olla huolellinen. Myös Terminate After kannattaa asettaa kohtuullisen alas. Databricks-työkirjojen ajaminen onnistuu vaivattomasti Data Factoryn avulla, joten se toimii erinomaisesti orkestrointityövälineenä esitellyssä arkkitehtuurissa.
Seuraavassa osassa perehdytään Power BI:n hyödyntämiseen big data -analytiikassa.
Lue myös:
Databricksin hyödyntäminen big data -analytiikassa (1/5) – Arkkitehtuuri
Databricksin hyödyntäminen big data -analytiikassa (2/5) – Kehitys
(Blog in English coming soon...)