
Marko Oja
Marko helps customers to understand the endless possibilities of technology and to transform innovative ideas into technical solutions. Agile methods and process development are close to his heart.
A week after I started to write the first blog post covering Great Expectations framework, I am back at it again. I managed to first create a custom expectation (i.e., a custom data validation rule) and after which I investigated the more formal way of using the framework. Here’s how it went and what I learned.
It’s been few days since I started to investigate Great Expectations and I have finally managed to create my first every custom expectation. I have to say I didn’t find a single documentation that would have shown me what exactly should be done, but rather combined bits and pieces from here and there. I’m very proud of my accomplishments but at the same time annoyed that I had to use so much time to get to this point. Even the documentation describing how to create a non-Spark custom expectation was somewhat cryptic, to say at least. Again, maybe it’s just me not being a good enough Python coder but creating custom rules doesn’t seem that complex and I can’t think of an excuse for it not being documented better. I even tried reaching out to the community but didn’t get any help, not even a single reply. Instead, I ended up helping an Indian coder with his problems.
Now that I have unloaded my frustration, let’s dive into the world of custom expectations! The optimal situation is that the framework has all the bells and whistles readily available (and GE might have most of what I need), but sooner or later I will need to be able to extend the functionality with my own implementation. The framework needs to support doing the necessary modifications when the time comes. Great Expectations promises that modifiability at least on paper.
I tried to read the documentation regarding how to create the custom bits but good Databricks and PySpark examples were scarce. After a while it got to the point where I had no other option but check the source code to get a clue. This turned out to be the winning strategy. Finding the answer might be a small victory, but a victory nonetheless. I found out how to get the data out as spark data frame inside the custom expectation. This is how my sweet piece of code looks like:
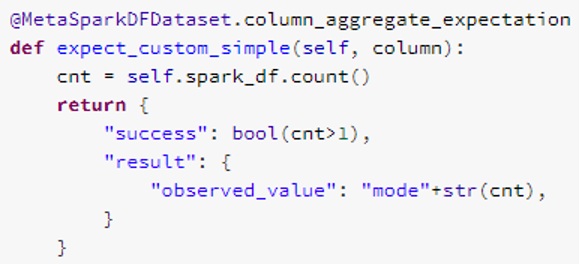
The thing I did not find documented anywhere was the self.spark_df that exposes the underlying data frame that was used for calling the expectation. It’s a small thing but it took some effort to figure it out. Now I’m trying to understand how to return results from my custom expectation. I’m getting into the same deep rabbit hole once again.
I did find a way to return custom details with the results after some trials and errors. I didn’t find documentation of which parts of the results are generated automatically by the framework or how to fill out all the “standard parts”. As of now I have a working work-around. It’s not ideal but in case this is as far as I can stretch the framework it’s something that can be accepted. So I will move on to finding out how I should formally do things with GE.
One extremely helpful blog article that I found was this one by Andreas Hopfgartner, who has been writing about Great Expectations already in 2019 meaning that he has been in the game for some time already.
https://medium.com/codex/pythonic-data-pipeline-testing-on-azure-databricks-2d27d3b5d587
The source code in the blog post helped me understand what I was missing in order to get the “full” experience. The article also explains how to setup a batch process. In a data platform pipeline that already provides a batch of data which I want to evaluate it doesn’t make much sense to create one again with GE. Anyway, if you are looking for source code to help with Databricks installation and usage then this article is worth checking out.
The article suggested some good practices for how the framework should be used. To begin you define your data source by describing a storage, a database or whatever you’re using. There are many options available for how to do this. Databricks can be used as an in-memory data source (my personal preference) or you can, for example, connect directly to a storage account. The latter might be a better option if you are not working with refined data pipelines. The next step is setting up the data context where you define stores for results, configurations, and such. And finally, you can either use a data batch or call the validation process directly with the expectations you want to use.
After these steps are done you will have the validation results in JSON file and in a html for human readable format. I would probably not use the full experience, though, if I was going to plug Great Expectations as a part of my data pipeline. For that scenario running the validation and handling the results directly in the pipeline might be a more viable solution. At minimum I would need to store the unexpected issues somewhere to be merged into the actual data model.
Let me start by saying that I am evaluating Great Expectations from a data platform architect´s point-of-view, which is probably not what the framework was originally designed for. Most of the documentation explains how to use the CLI to setup things so that you can execute the validation rules. This feels like a lab environment setup and for that purpose I believe it works very nicely. If you are fluent in Python and doing initial testing to help validate your development data, then the framework should be a good fit. In terms of a data platform usage there are a few things that are less than perfect.
The things that I miss:
While these imperfections might not be an issue for ML data validation in the development phase, they do propose some problems for using the framework in a data platform production environment. Although I have found workarounds for these shortcomings, they left me with some reservations towards the framework. That’s the ugly part. Fortunately, there is a lot to love as well.
Things I liked:
As final words, having any method to perform data quality validation is a good start and much better than having nothing at all. But having a framework-backed template to validate the data quality is in its own league. That alone is enough justification for this framework which has a lot of useful features. How or if this will fit to an existing data management framework however is something that needs to evaluate before adaptation decision is made.
Thank you for reading through my ramblings and experiences with the evaluation work. I hope you found it at least somewhat insightful. If you have any comments or questions, please contact me on LinkedIn or in the Great Expectations slack. I would be happy to hear your thoughts and questions about the framework or experiences in data quality in general.