Marko Oja
Data-arkkitehti, joka auttaa asiakasta ymmärtämään tekniikan mahdollisuudet ja muuntaa innovatiiviset ideat teknisiksi ratkaisuiksi. Ketterät kehitysmenetelmät ja kehitystyötä tukevat prosessit ovat lähellä Markon sydäntä.
Microsoft's newest offering to Azure's Data Stack is Azure Synapse. This product has just hit public preview, but I am sure most of you have heard about it all ready. We were lucky enough to have the privilege of participating to the private preview and even before that to the development phase of SQL On-demand feature.
In the private preview phase, we got the opportunity to test Synapse's capabilities with Kemira by creating a PoC solution for IoT data processing. It is quite usually much more rewarding to do this kind of testing with actual production data and in the actual customer environment instead of using something that has just been created for demo purposes. So we value highly the possibility to test out new features with our partners because it not only gives our partner more understanding how it may benefit them but also gives us much more deeper understanding about the true capabilities, features and possible issues we might be facing in real life scenarios.
Well, before I introduce the case we did, a few words about the Synapse itself. I will not be going into details about what it all means but to give you an idea what Synapse offers in general if you are not already familiar with it. Behind the curtains Synapse brings key features of Azure's data stack under one product and adds few features not seen before. Those we are most familiar with are the data warehouse and SQL pools, Data pipelines as in Data Factory and Power BI. Less familiar features are Synapse Spark which is like Data Bricks and SQL On-demand (later SQL OD) which is something totally new. It is a serverless service (in terms of that you do not pay for cluster up-time) for querying (and now also for writing) for example files into the blob storage. Also, the cool part is that there is functionality between the services like ability to use the same spark table from SQL OD without running the spark cluster itself.
So, in a nutshell Synapse offers all the tools needed to do end to end data platform ETL and ELT work for batch and real time data streams. Including analysis and reporting.
Well we were (and still are) most excited about the SQL On-demand feature as it was something that has not been available in the Microsoft stack before. It is a virtualization layer for different data sources to wrap them under one service so that the end user look feel remains like with a traditional SQL database. We ended up doing the PoC solution around SQL OD.
For the data source of this PoC, we had the opportunity to use Kemira's Oulu's factory IoT data stream. Sensor data from the factory comes to Azure through IoT Hub and is stored into Data Lake Storage. Current solution uses python code to transform the message into a CSV file which can be loaded into SQL DW.
We wanted to see what it would mean to remove the code from this solution by replacing that part with SQL OD. Second thing we wanted to see was if we can utilize the SQL OD as a direct query data source for Power BI dashboard. To get it refresh every 15 min (Power BI minimum refresh cycle for dashboards) instead of the few hours cycle which was supported with the old solution. Third objective was also to see how SQL OD would work as a data source for Power BI in the PoC as it would be used in a data validation phase of a normal development process.
Our architecture looked like this at the end:
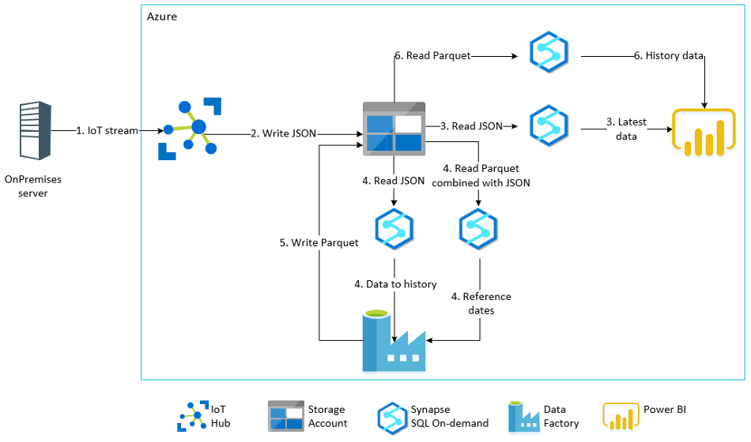
1.–3. Data is streamed to Power BI via Storage account using SQL OD to virtualize JSON files as SQL view
4.–5. Data is loaded by virtualizing the files as SQL views with SQL OD and then loaded back to Parquet files into the storage account
6. Finally the history data is loaded to Power BI using SQL OD to virtualize Parquet files as SQL view
Kemira is bringing the data from its factory in Oulu to Azure for further analysis. Operation system have good real time monitoring features to run operations smoothly. However, to analyse data across over a year or longer time span a more detailed and flexible solution is needed. Also linking the data with information from other internal sources like ERP-system cannot be achieved in the local environment. Azure data platform services are used to stream the data into the data platform and to provide it for analysis through Power BI. In the future more solutions like this will also be created. To support these upcoming projects ingestion, initial validation and monitoring implementations are needed. Easy to use and fast to develop tool would help to achieve this target. Azure Synapse and especially the SQL OD will hit just that spot.
First of all if you want a really good performance you should store your files in parquet format. Other formats are fine if you don’t have much data or don’t want to run fast queries like in direct query queries from Power BI.
Secondly SQL OD help so much with the ELT work. We saved files from IoT Hub to storage in JSON format and this was our “latest data” source for Power BI. To get last year data from several tens or hundreds of gigabytes of data to perform with a Direct Query we had to save files into parquet. We did this with only a single view in SQL OD and one copy activity in Data Factory. For a data engineering perspective this really gave a wow effect. But I think you must be a data nerd to appreciate the simplicity of the solution. For others this just means implementation that is more flexible and easier to maintain.
Thirdly SQL OD perform quite well as a static data source. For the Direct Query it’s a bit behind SQL DW but is still very much usable. You will be waiting for several seconds for responses, but this is with a data that has not been modelled or loaded to anywhere after the initial storage layer. Meaning that you don’t have to do or think modelling for the data validation part of a project. This a feature that DataOps projects will be thankful to have.
We are also seeing a huge investment and thrive from Microsoft to push this feature forward. It will be so interesting to see which all features will be ready for the public preview (as I am writing this before it has started) and for the actual release as well.
If you are interested to hear more about the possibilities of Azure Synapse or what else Azure can help you to accomplish you can contact me by email.

The Kemira of today focuses on serving customers in water intensive industries: pulp & paper, municipal and industrial water treatment and oil gas. Kemira has units operating in 40 countries, represented by skilled personnel from over 60 nationalities. Kemira has over 4800 employees globally.

Cloud1 assists companies that want to gain a competitive advantage through digitalization. We bridge the gap between business operations and technology to make it easier to leverage new digital solutions in business.

Azure Synapse is a limitless analytics service that brings together enterprise data warehousing and Big Data analytics. It gives you the freedom to query data on your terms, using either serverless or provisioned resources—at scale. Azure Synapse brings these two worlds together with a unified experience to ingest, prepare, manage, and serve data for immediate BI and machine learning needs.