Organisatoric data and reporting secrets revealed
Where does this data actually come from?
What happens to it – is this what I see in the same format and named similarly as at the source?
Do I see everything?
Do others see the same as I do, with same names and valuation without nothing being filtered or removed?
Who on earth owns this data and is responsible of it?
Where this data is being used and how?
Do any sort of transformations or processing happen to the date before it reaches this report?
If I want to enrich this report further, do we have and own all the required sources already?
Multiple questions that all tie back to the same single root cause: quite often it is extremely hard to grasp the big picture and even find out all the puzzle pieces that are required to create the tangible end result, for example in the form of a report. How this problem can be tackled and gain some clarity?
The offering
To map the organisatoric data assets features and attributes multiple tools and applications have been developed over time, that all share the common umbrella term of ’data catalog’. In the simplest form these catalogs have been maintained for example with Excel, that is common tool to all of us. However, regardless of the approach and chosen tool, the features within and scope has been limited as well as usability has not been that easy.
Azure Data Catalog Gen1 was Microsoft’s previous step on the path to bring more visibility and transparency to data assets from organization’s perspective, but alike other products had it’s limitations regarding usability. In the beginning of Dec 2020 Azure Data Catalog Gen2 was released for Public Preview and was simultaneously re-branded as Purview. Purview is a big leap forward in terms of usability, controllability, visuality and extendabiity.
Purview
Purview automatizes a large portion of the whole process by scanning data sources defined and classifying the findings by utilising built-in (including GDPR related such as individual’s name, passport number, email address, credit card number etc.) as well as custom classifications defined by the organization. The end result is served visually via different graphs to understand the big picture. In high level the process is as simple as:
- Define datasources
- Define scanning parameters
- Initiate scanning
The resulting classification outcome is presented visually as per below image:
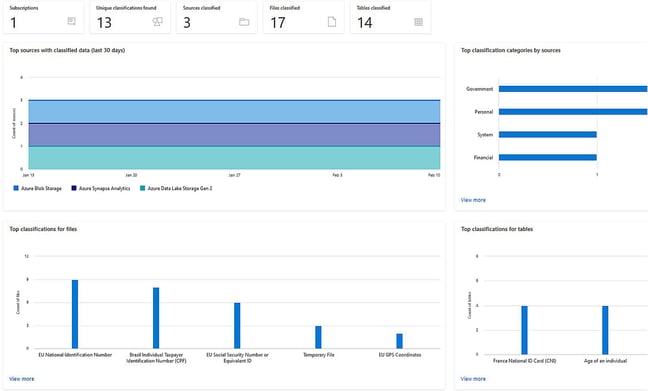
It is worth to note, that classification that is based on algorithms can always produce false-positives ie. classifying data incorrectly due to some random string found in the data. Nevertheless even a single scan can produce information what sort of data the organization has, which assets are sensitive and potentially require special attention in form of anonymisation and data access. This sort of information is golden.
Classifications are included in Purview’s search functionality, so datasets flagged with a certain classification are easy to find. For example, searching for term ’EU national’ found in above example image, datasets flagged with this classification are returned regardless of the storage type.
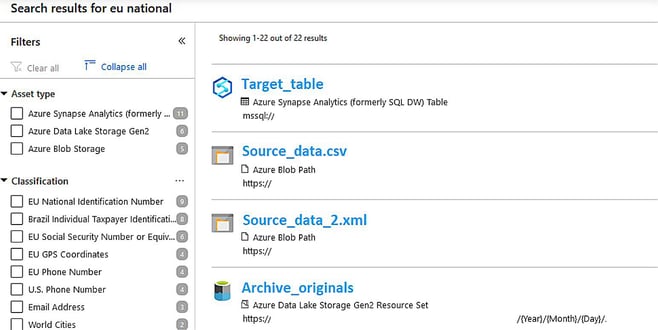
Sources
Purview supports a large number of source systems natively by offering connectors to many non-Microsoft products such as SAP, AWS S3, Teradata etc. At the time of writing datacenters available in Finland only offer Azure based resources such as SQL Server, Synapse, ADLS etc. This list is growing and quite possibly is more comprehensive by the time Public Preview ends by the end of February.
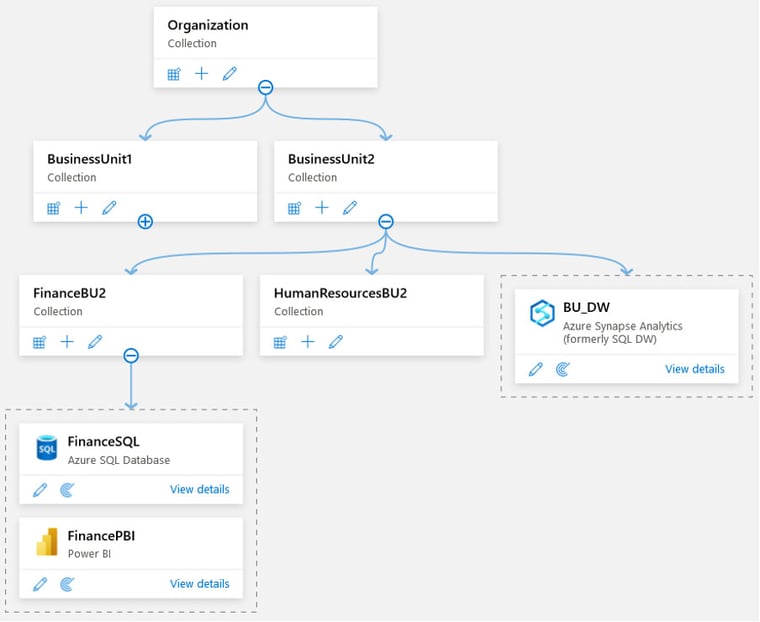
From organizatoric data assets management perspective Purview offers a possibility to create ”collections” as per below image. Main collection can have sub-collections, that can contain further sub-collections etc. Each collection regardless of level, can contain also source connection definitions, that can be used in the scans. Collections are excellent way to organize and manage systems, that do not potentially follow formal naming convention or have become part of organization’s data asset via company merger for example.
Data lineage
One of the most important features Purview brings into the toolbox is data lineage presentation visualised and automated. At the time of writing Purview can create complete end-to-end data lineage from source to consumer under certain conditions. These conditions are:
- Scanning source is one of Azure service (blob, sql, dw)
- Orchestration is done using Data Factory and only the following activities are used:
- Pipeline
- Data flow
- SSIS package (custom packages are not supported yet)
- Consumer is PowerBI report
Even though the limitations are these at the time of writing, it is to be expected that more source types as well as process elements will be supported at some stage, including widely used SQL stored procedures, Databricks processing etc.
Purview is based on Apache Atlas which means all Atlas REST APIs are also exposed and are usable for querying and enrichment. This enables manual data lineage enrichment via REST APIs for example with processes that are not yet supported by Purview automatically. Such processes are SQL stored procedures, ML modeling, Databricks processes etc.
Below is an example of enriched data lineage: process XXX has been added to Purview’s catalog and has been linked to two datasets: source and target.

The same lineage below from the source perspective, which enables user to follow attribute level changes during the process. This brings attribute name changes, potential tranformations documentation etc. at attribute level easily to easily manageable and understandable format.

Management
Data Catalog Gen1 was limited only to one per Azure Tenant, which meant that use cases and scope had to be defined really carefully. With Purview, the number of instances is not limited but instead multiple instances are are allowed within same Tenant and even Subscription.
One potential use case is to have dedicated Business Unit instances as well as global scope ’data platform’ instance with carefully thought over access model. Linking individual Purview instances together is one potential usability addition which would create instant value, but whether this will be added is not known at the time of writing.
Purview offers three custom roles for different users. ‘Purview Data Reader Role’ is purely consumer type role and grants ability to read data. ‘Purview Data Curator Role’ is meant for resource management and asset commentary, classification and business glossary maintaining etc. ‘Purview Data Source Administrator Role’ does not contain any of above and is solely meant for defining scans and potentially to manually trigger scans. Combination of these three grant desired used access level.
Purview’s model enables and softly ”forces” to set up organizatory responsibilities regarding data correctly. It pays off to utilize this chance and really concentrate on putting data & process ownerships, data domain and business unit roles into shape. Properly planned and designed base paves way to succesfull utilisation of the tool far into future.
Purview is part of Cloud1’s Architecture Governance / Data Management toolbox.
Links: